There are cases where you may want to have your own scheduling algorithm. For example, you may want a pod to be placed on a certain node depending on additional checks. In this case, the default scheduler does not cut it.
- K8s is highly extensible; you can make your custom scheduler become the default scheduler or run it as an additional scheduler.
When creating a pod or a deployment, you can instruct K8s to have the pod scheduled by a specific scheduler.
- When there are multiple schedulers, they must have different names so that they can be identified as separate schedulers.
- The default scheduler doesn’t need the “schedulerName” attribute defined because when it isn’t defined, it is assumed that it is the default scheduler. If you want, you can define it like so:
scheduler-config.yaml:
apiVersion: kube-scheduler.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
Deploying Additional Schedulers
Create an additional custom scheduler similarly:
custom-scheduler-config.yaml:
apiVersion: kube-scheduler.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: custom-scheduler # This is the only difference from above
To deploy these Schedulers, you could download the scheduler service binary and then run the binary as a service with a set of options:
$ wget https://storage.googleapis.com/kubernetes-release/release/v1.15.0/bin/linux/amd64/kube-scheduler
kube-scheduler.service
ExecStart=/usr/local/bin/kube-scheduler
--config /etc/kubernetes/config/kube-scheduler.yaml
-
Or point the service to the custom configuration:
custom-scheduler.service
ExecStart=/usr/local/bin/kube-scheduler
--config /etc/kubernetes/config/custom-scheduler.yaml # This is the difference
Now, each scheduler utilizes the custom configuration and has its own name.
- Note: There are other options that could be passed in as well.
The previous method of creating multiple schedulers is not the way you would deploy a custom scheduler 99% of the time today because with kubeadm deployment, all the control plane components run as a pod or a deployment within the Kubernetes cluster.
Deploying Additional Schedulers as Pods
To deploy additional schedulers as pods:
- Create a pod definition file and specify the
--kubeconfigproperty, which is the path to the scheduler’s configuration file that has the authentication information to connect to the Kubernetes API Server. - Pass in the custom Kube-scheduler configuration file as a command option to the scheduler.
- Note that we have the same scheduler name specified in the file, so that’s how the name gets picked up by the scheduler.
This is a sample pod definition file (1):
custom-scheduler.yaml
apiVersion: v1
kind: Pod
metadata:
name: custom-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --address = 127.0.0.1
- --kube-config=/etc/kubernetes/scheduler.conf # From step 1
- --config=/etc/kubernetes/custom-scheduler-config.yaml # From step 2
image: k8.gcr.io/kube-scheduler-amd64:v1.11.3
name: kube-schduler
And a custom kube-scheduler configuration file (2):
custom-scheduler-config.yaml
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: custom-scheduler
leaderElection:
leaderElect: true
resourceNamespace: kube-system
resourceName: lock-object-custom-scheduler
Taking a closer look into the custom scheduler config definition file below, another thing to take note of is the leaderElection option. The leaderElection option is used when you have multiple copies of the schedulers running on different master nodes as a high-availability setup.
- If multiple copies of the same scheduler are running on different nodes, only one can be active at a time, and that’s where the
leaderElectionoption helps in choosing a leader who will lead the scheduling activities.
Deploying a Scheduler as a Deployment
To deploy the scheduler as a deployment, you could first clone the Kubernetes repo:
$ git clone https://github.com/kubernetes/kubernetes.git
$ cd kubernetes
$ make
- Then, make changes to the Kube scheduler and create a Dockerfile to build the image:
Dockerfile:
FROM busybox
ADD ./_output/local/bin/linux/amd64/kube-scheduler /usr/local/bin/kube-scheduler
- Now, you can build the image and push it to a registry:
`$ docker build -t gcr.io/my-gcp-project/custom-kube-scheduler:1.0 .
- The image name and the repository
$ gcloud docker -- push gcr.io/my-gcp-project/custom-kube-scheduler:1.0 - Used in here is just an example
- The image name and the repository
- Now that you have a scheduler in a container image, create a pod configuration for it and run it in your Kubernetes cluster. But instead of just creating a pod directly in the cluster, you can use a Deployment, which manages a ReplicaSet, which in turn manages the pods, thereby making the scheduler resilient to failures.
- The pod configuration looks similar to the new deployment configuration since pods are defined in deployments and replica sets.
custom-scheduler.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: scheduler
tier: control-plane
name: my-scheduler
namespace: kube-system
spec:
selector:
matchLabels:
component: scheduler
tier: control-plane
replicas: 1
template: # Start of the pod template
metadata:
labels:
component: scheduler
tier: control-plane
version: second
spec:
serviceAccountName: my-scheduler
containers:
- command:
- /usr/local/bin/kube-scheduler
- --config=/etc/kubernetes/my-scheduler/my-scheduler-config.yaml
image: gcr.io/my-gcp-project/custom-kube-scheduler:1.0
In order for this to work, there are other things that need to be put in place, such as cluster role bindings and service accounts. These will be covered more later, but at a high level, cluster role bindings and service accounts help ensure that your scheduler has the necessary privileges to do its job without compromising security.
Moving on, the file used in the --config option can be passed into the deployment in one of two ways:
- Create this file locally and pass it in as a volume mount.
- This is a straightforward approach where you create the configuration file locally, and then mount it as a volume inside your deployment pod.
- This is suitable for scenarios where the configuration file is static and doesn’t change frequently.
- Create a ConfigMap and pass it in as a volume mount.
- ConfigMaps are Kubernetes resources that allow you to decouple configuration artifacts from your containerized applications.
- This is beneficial when you want to manage configurations dynamically or update them without redeploying your application.
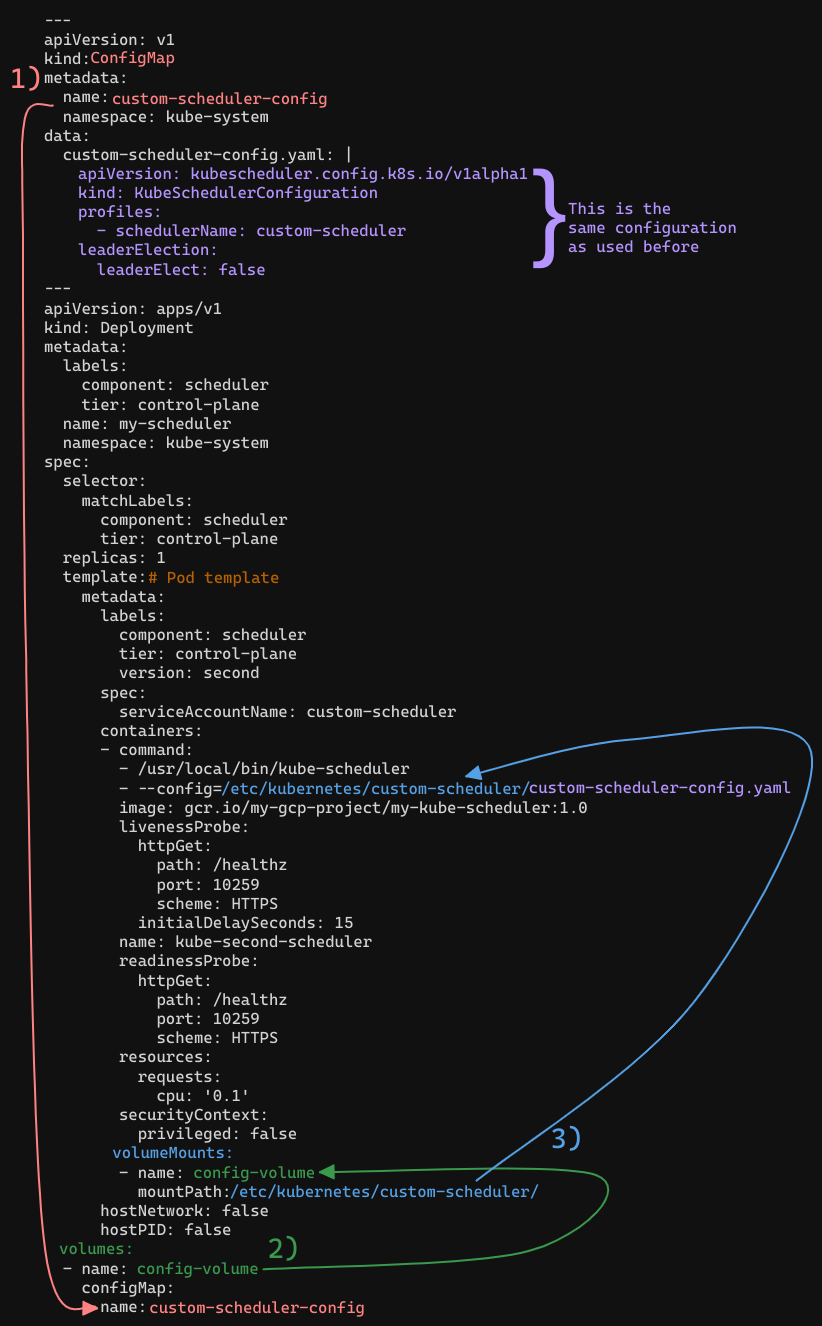
Pass a ConfigMap as a volume mount:
The ConfigMap (1) is used as a Volume (2) and that Volume is mounted (3) and then used in the --config option of the - command
custom-scheduler.yaml:
View Schedulers
You can see schedulers that are deployed as pods and deployments using:
$ kubectl get pods --namespace=kube-system- Note that schedulers deployed as a deployment will have a slightly different naming convention than pods
Use Custom Schedulers
Finally, once you deploy the custom scheduler, you can set a pod to use the custom scheduler by using the “schedulerName” attribute in the pod definition file and then creating the pod using:
$ kubectl create -f pod-definition.yaml
pod-definition.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
schedulerName: my-custom-scheduler # This tells the pod to use the scheduler
If the pod wasn’t scheduled correctly, it will show as in a “Pending” state.
- To make sure the pod was scheduled correctly, run:
$ kubectl get events -o wide - This will show all of the events, including which pods are scheduled to which nodes using which scheduler.
- You can also view the logs to get this info:
$ kubectl logs my-custom-scheduler -n kube-system