Before we dive into persistent volumes, let’s start with the basics of volumes in Kubernetes by first looking at how volumes work in Docker.
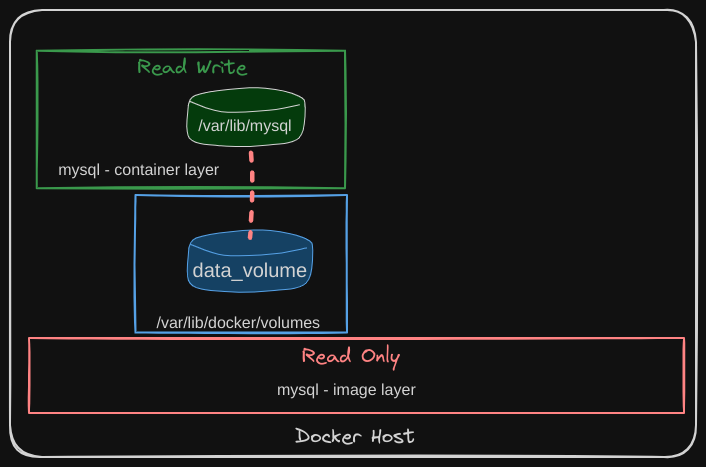
We discussed before that Docker containers are designed to be transient, meaning they are meant to last only for a short period. They are created to process data and then destroyed once their task is completed. This transient nature extends to the data within the container, which is lost when the container is deleted.
To persist data processed by Docker containers, volumes are attached to the containers at creation. This way, the data is stored in the volume and remains even if the container is removed. For instance, any data generated by the container is placed in this volume, ensuring data retention.
Volumes in Kubernetes
Just like Docker containers, Kubernetes pods are also transient. When a pod is created to process data and then deleted, the data processed by it is also deleted. To persist data in Kubernetes, a volume is attached to the pod. The data generated by the pod is stored in the volume, ensuring it remains even after the pod is deleted.
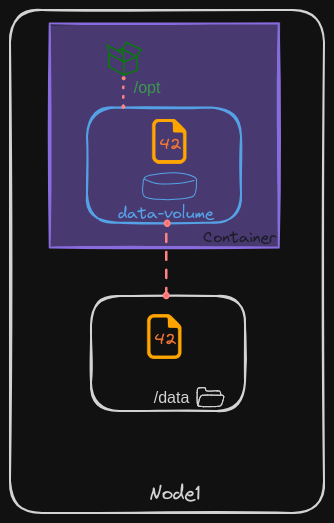
Consider a single-node Kubernetes cluster. We create a simple pod that generates a random number between 1 and 100, writing this number to a file at /opt/number.out. Normally, when the pod is deleted, this file is lost.
pod-definition.yaml
apiVersion: v1
kind: Pod
metadata:
name: random-number-gen
spec:
containers:
- image: alpine
name: alpine
command: ["/bin/sh", "-c"]
args: ["shuf -i 0-100 -n 1 >> /pot/number.out;"]
To retain the generated number, we use a volume. When creating a volume, we need to specify its storage. There are various storage configuration options available.
- For simplicity, we will configure the volume to use a directory on the host. For example, we specify the path
/dataon the host. Any files created in the volume will be stored in the/datadirectory on the host.
pod-definition.yaml
apiVersion: v1
kind: Pod
metadata:
name: random-number-gen
spec:
containers:
- image: alpine
name: alpine
command: ["/bin/sh", "-c"]
args: ["shuf -i 0-100 -n 1 >> /opt/number.out;"]
volumes:
- name: data-volume
hostPath:
path: /data
type: Directory
Once the volume is created, we mount it to a directory inside the container using the volumeMounts field. In this case, we mount the volume to /opt within the container.
pod-definition.yaml
apiVersion: v1
kind: Pod
metadata:
name: random-number-gen
spec:
containers:
- image: alpine
name: alpine
command: ["/bin/sh", "-c"]
args: ["shuf -i 0-100 -n 1 >> /opt/number.out;"]
volumeMounts:
- mountPath: /opt
name: data-volume
volumes:
- name: data-volume
hostPath:
path: /data
type: Directory
The random number will now be written to /opt/number.out inside the container, which is actually stored in the /data directory on the host.
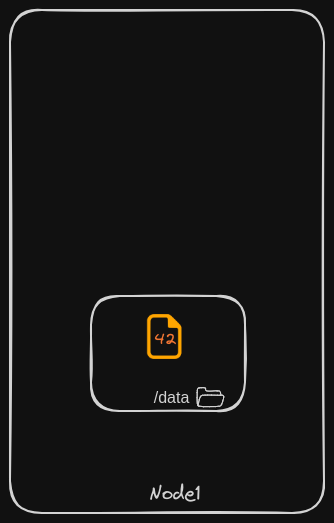
When the pod is deleted, the file with the random number still exists on the host.
Volume Storage Options
Using the hostPath option for volume storage works fine for a single-node cluster but is not recommended for multi-node clusters. This is because each node in the cluster would use its own /data directory, leading to inconsistencies.
Kubernetes supports various storage solutions, such as:
- NFS
- GlusterFS
- Flocker
- Fiber Channel
- CephFS
- ScaleIO
- Public Cloud Solutions: AWS EBS, Azure Disk or File, Google Persistent Disk
Example: AWS Elastic Block Store (EBS)
To use an AWS Elastic Block Store (EBS) volume, replace the hostPath field of the volume with the AWS EBS configuration, specifying the volume ID and file system type. This ensures that the volume storage is on AWS EBS.
pod-definition.yaml
apiVersion: v1
kind: Pod
metadata:
name: random-number-gen
spec:
containers:
- image: alpine
name: alpine
command: ["/bin/sh", "-c"]
args: ["shuf -i 0-100 -n 1 >> /opt/number.out;"]
volumeMounts:
- mountPath: /opt
name: data-volume
volumes:
- name: data-volume
awsElasticBlockStore:
volumeID: <volume-id>
fsType: ext4
In this setup, the data processed by the pod is stored on AWS EBS, ensuring persistence across pod deletions and cluster nodes.
By understanding how volumes work in Kubernetes, you can ensure data persistence and proper storage configuration, whether using local directories or advanced storage solutions.