High Availability in Kubernetes
What happens when the master node in your Kubernetes cluster goes down? While your applications may continue running on worker nodes as long as the containers are functional, the situation becomes critical if a pod or container crashes. Without the master node, there’s no mechanism to recreate the pod or schedule it on other nodes. This is why high availability (HA) is essential for production-grade Kubernetes environments.
The Need for High Availability
High availability ensures that no single point of failure disrupts your cluster’s operations. It involves building redundancy across all critical components, including master nodes, worker nodes, control plane components, and even applications (already addressed through replicas and services). This post focuses on achieving HA for master nodes and control plane components.
Multiple Master Nodes
In a typical Kubernetes setup, a single master node hosts all the control plane components—API server, controller manager, scheduler, and ETCD. In an HA configuration, multiple master nodes are deployed, each running the same set of components.
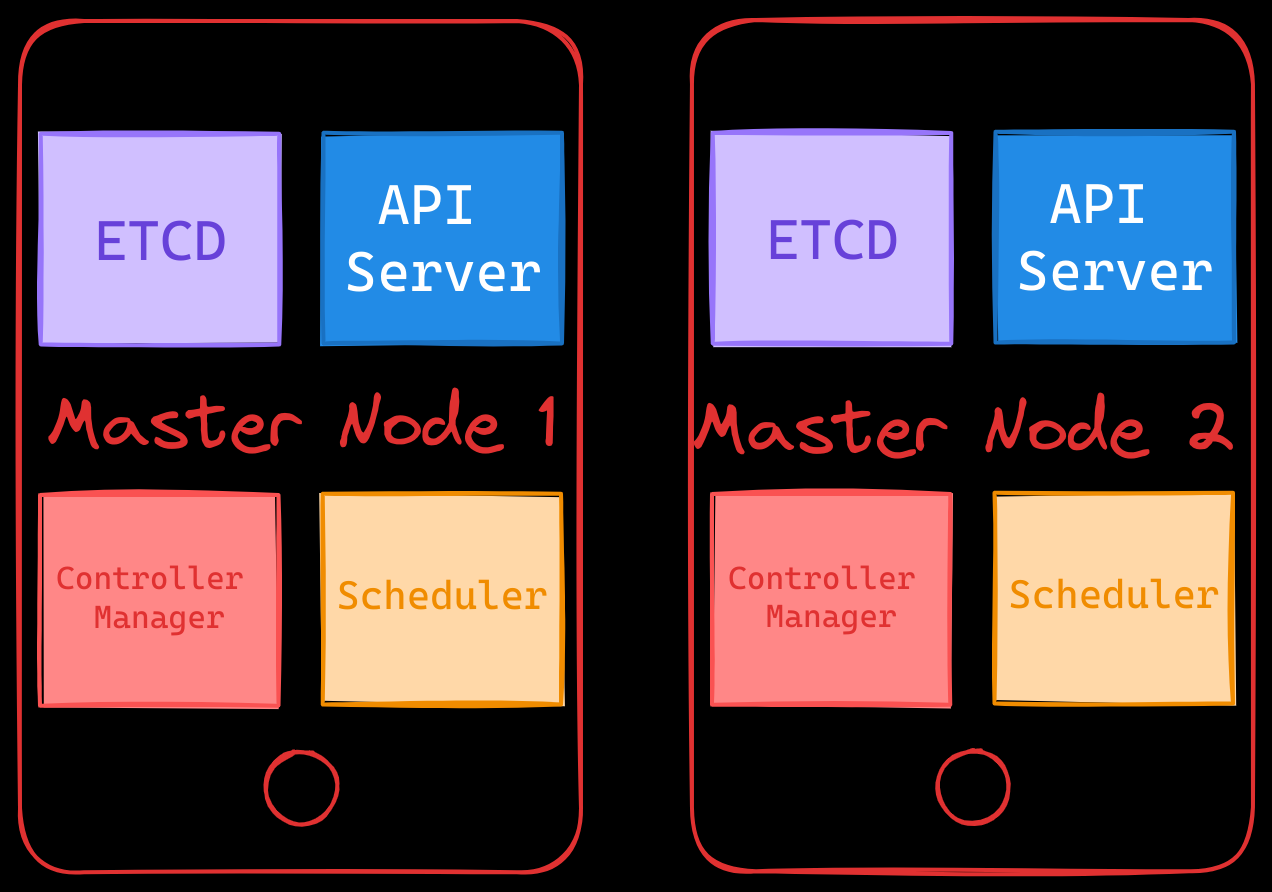
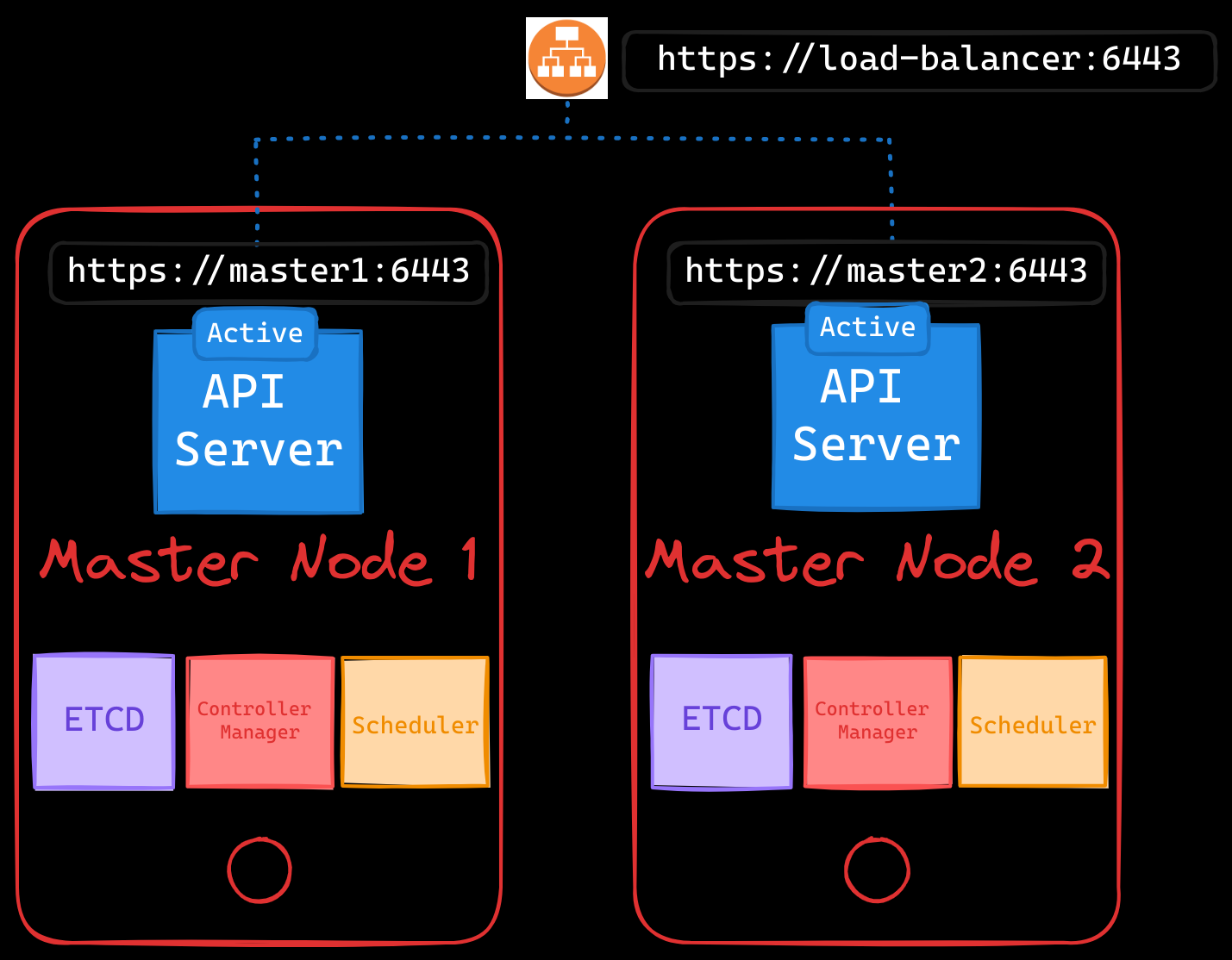
API Server
The API server handles all requests and acts as the communication hub for the cluster. In an HA setup, multiple API servers operate in active-active mode. To ensure smooth distribution of requests, a load balancer is used to route traffic among the API servers. Common load balancers include NGINX, HAProxy, or cloud-based solutions like AWS Elastic Load Balancer.
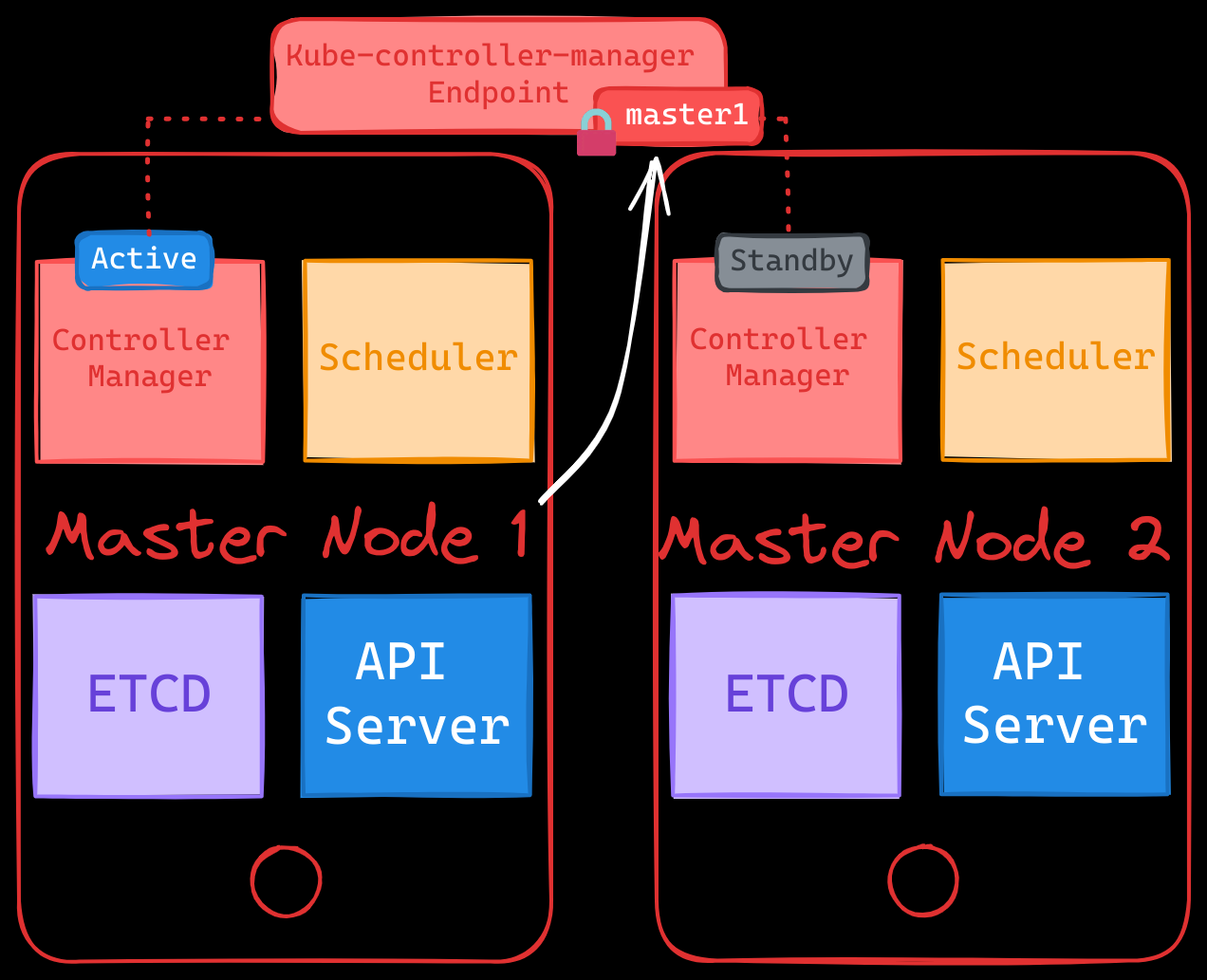
Controller Manager & Scheduler
The scheduler and controller manager continuously monitor the cluster’s state and take action when needed, such as creating a new pod to replace a failed one. These components function in an active-standby mode to prevent duplicate actions.
- Leader Election:
- A leader election mechanism determines which instance of the controller manager or scheduler is active.
- The active instance gains a lease on an endpoint object (e.g.,
kube-controller-manager), while other instances remain passive, on standby. - The lease’s duration and renewal are configurable, ensuring a seamless failover if the active instance fails.
To create the kube-controller-manager with leader election enabled, you can use the following command:
$ kube-controller-manager --leader-elect=true \
--leader-elect-lease-duration=15s \
--leader-elect-renew-deadline=10s \
--leader-elect-retry-period=2s \
[other options]
--leader-elect=true: Enables leader election to ensure only one active instance of the controller manager.--leader-elect-lease-duration=15s: Specifies the duration that non-leader instances wait to claim leadership after the active leader fails.--leader-elect-renew-deadline=10s: Sets the time the current leader has to renew its lease before leadership is forfeited.--leader-elect-retry-period=2s: Determines how often non-leader instances check the lease to try and become the leader.
The kube-scheduler behaves in a similar manner and uses the same command structure to enable leader election.
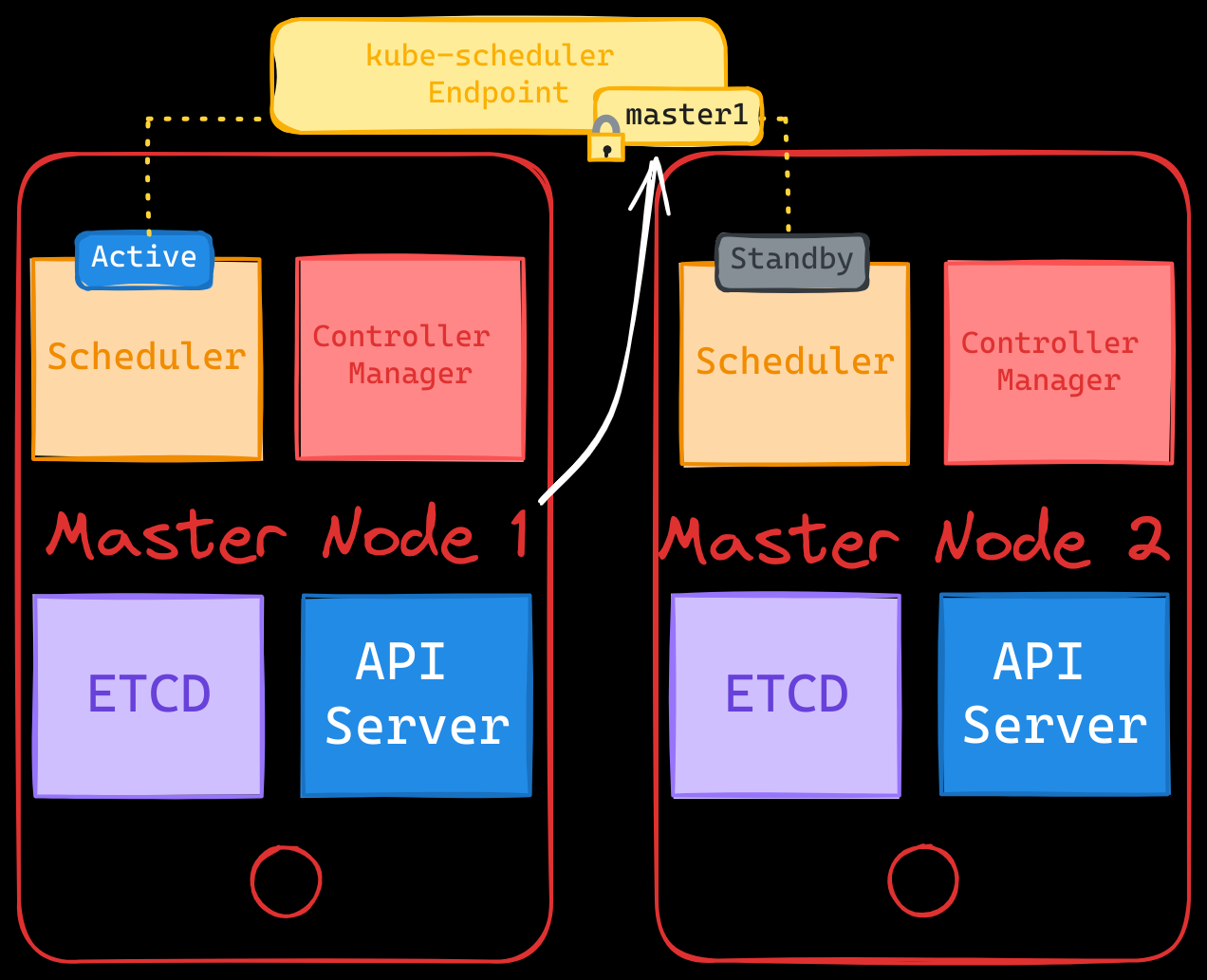
Here’s an example for the kube-scheduler:
$ kube-scheduler --leader-elect=true \
--leader-elect-lease-duration=15s \
--leader-elect-renew-deadline=10s \
--leader-elect-retry-period=2s \
[other options]
ETCD Topology
ETCD, the key-value store for Kubernetes, is a critical component that maintains the cluster’s state. Its reliability is paramount in an HA setup. Two common ETCD topologies include:
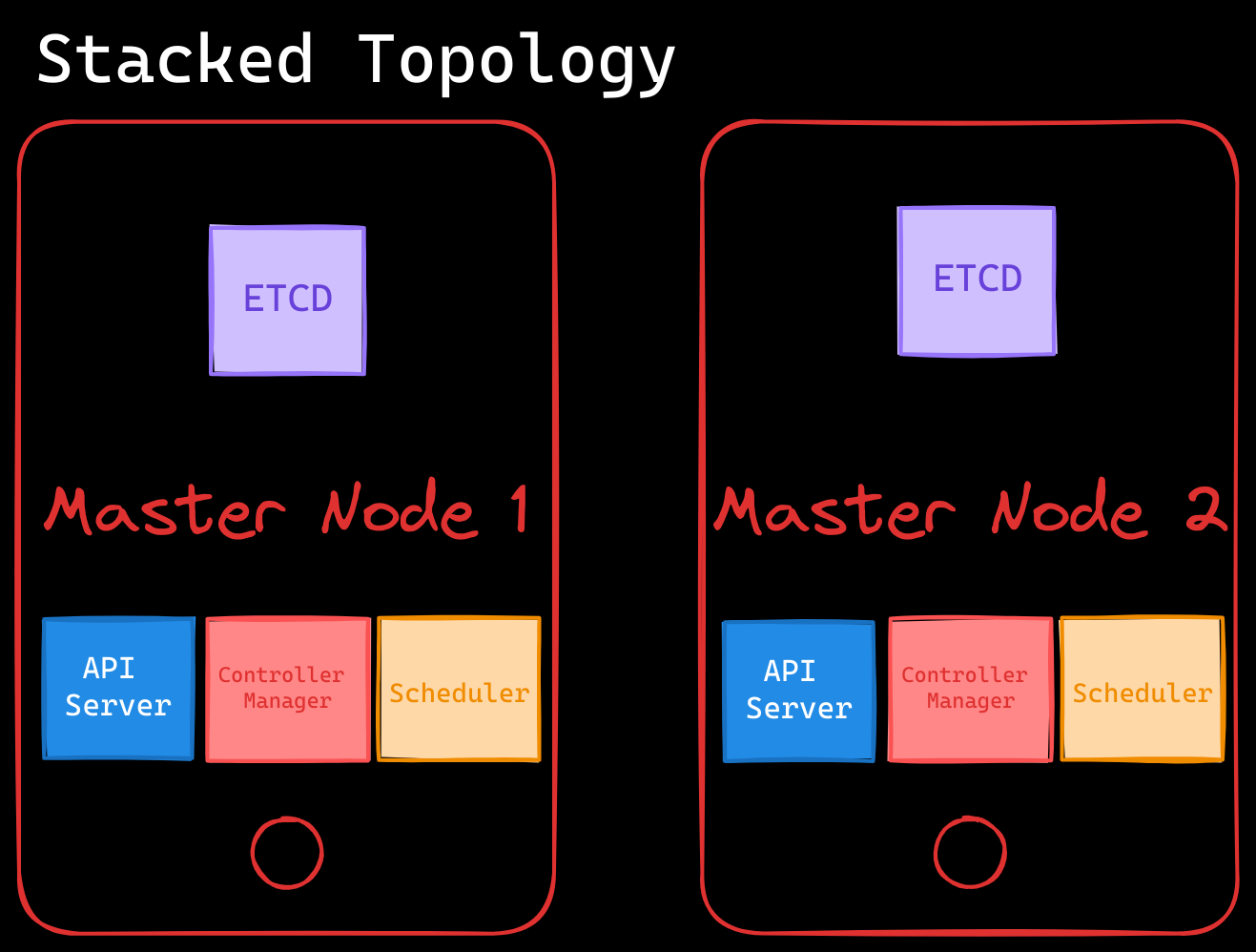
- Stacked Control Plane Nodes Topology:
- ETCD runs alongside control plane components on the same nodes.
- Easier to set up and manage but increases the risk of losing both the ETCD and control plane components if a node fails.
- External ETCD Nodes Topology:
- ETCD runs on dedicated servers separate from the control plane nodes.
- More resilient but requires additional infrastructure and is more complex to manage.
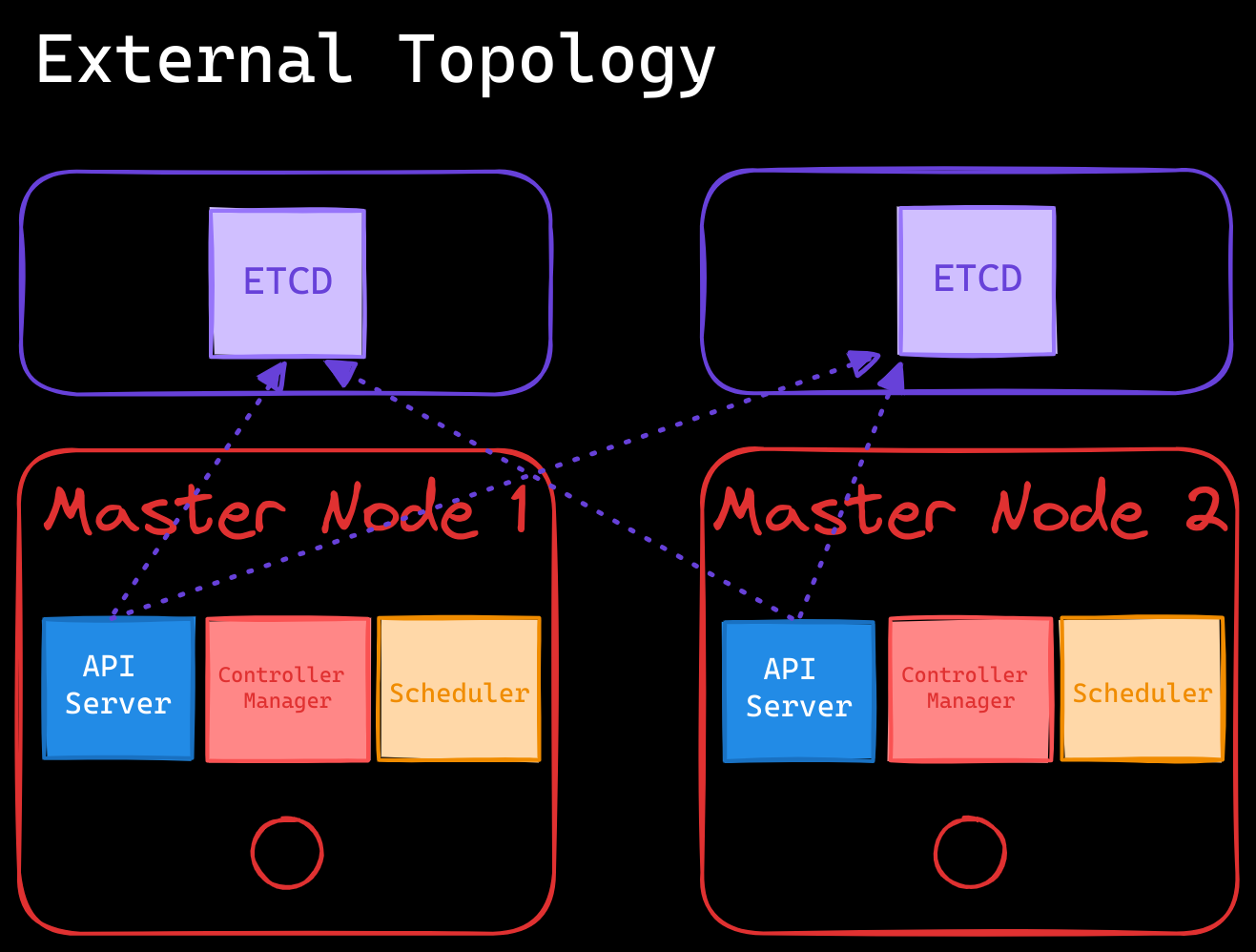
In both topologies, the API servers must be properly configured to connect to the appropriate etcd endpoints. In an External Topology, you need to specify the IP addresses of all etcd instances. This ensures that the API server (the only component that communicates directly with the etcd server) can reach any of the etcd cluster members.
$ cat /etc/systemd/system/kube-apiserver.service
[Service]
ExecStart=/usr/local/bin/kube-apiserver \\
--advertise-address=$(INTERNAL_IP) \\
--allow-privileged=true \\
--apiserver-count=3 \\
--etcd-cafile=/var/lib/kubernetes/ca.pem \\
--etcd-keyfile=/var/lib/kubernetes/kubernetes-key.pem \\
--etcd-servers=https://10.240.0.12:2379,https://10.240.0.13:2379
Conclusion
High availability is a cornerstone of production-grade Kubernetes clusters, ensuring the reliability and resilience needed to handle failures. Implementing an HA setup for control plane components, including the API servers and etcd, eliminates single points of failure and ensures that the cluster remains operational even in the face of node or component failures.
A critical component of this setup is etcd, which plays a vital role in maintaining the cluster’s state. Understanding its distributed nature, leader election process, and quorum requirements is essential for designing a resilient cluster. By carefully choosing the etcd topology—whether stacked or external—and configuring an odd number of nodes, you can achieve the fault tolerance necessary for high availability.
In the next post, we will transition from theory to implementation, exploring how to configure Kubernetes in a highly available mode with a focus on deploying and managing etcd in an HA setup.