Expanding on our earlier discussion of ETCD topologies, this post focuses on how ETCD achieves high availability (HA) in Kubernetes. As the core data store that maintains Kubernetes cluster state, ETCD plays a crucial role in ensuring consistency and reliability. Configuring ETCD for high availability is essential to eliminate single points of failure, whether you choose a stacked or external topology.
In this post, we’ll explore ETCD’s distributed nature, leader election, quorum requirements, and guidelines for cluster sizing in HA setups.
Recap: The Role of ETCD
ETCD is a distributed, key-value store that powers the state management in Kubernetes clusters. It is simple, secure, and optimized for speed and reliability. ETCD stores critical cluster information, such as node states, configuration data, and resource specifications.
Key Features of ETCD:
- Redundancy: Data is replicated across multiple nodes to ensure availability.
- Consistency: All nodes maintain identical copies of the data.
- Fault Tolerance: High availability ensures continued operations despite node failures.
The choice of deployment topology, stacked or external, defines how ETCD integrates with Kubernetes control plane components. Understanding its behavior and failure tolerance is crucial to achieving a robust setup.
Leader Election and Write Operations
How Leader Election Works
ETCD uses the Raft consensus algorithm to maintain data consistency and ensure only one node processes writes. The Raft protocol elects a leader node responsible for coordinating writes while the other nodes act as followers.
Election Process:
- Nodes start with random timers.
- The first node whose timer expires requests votes to become the leader.
- A quorum (majority) of nodes must agree for the leader to be elected.
If the leader fails, a re-election process begins to select a new leader, ensuring continuity.
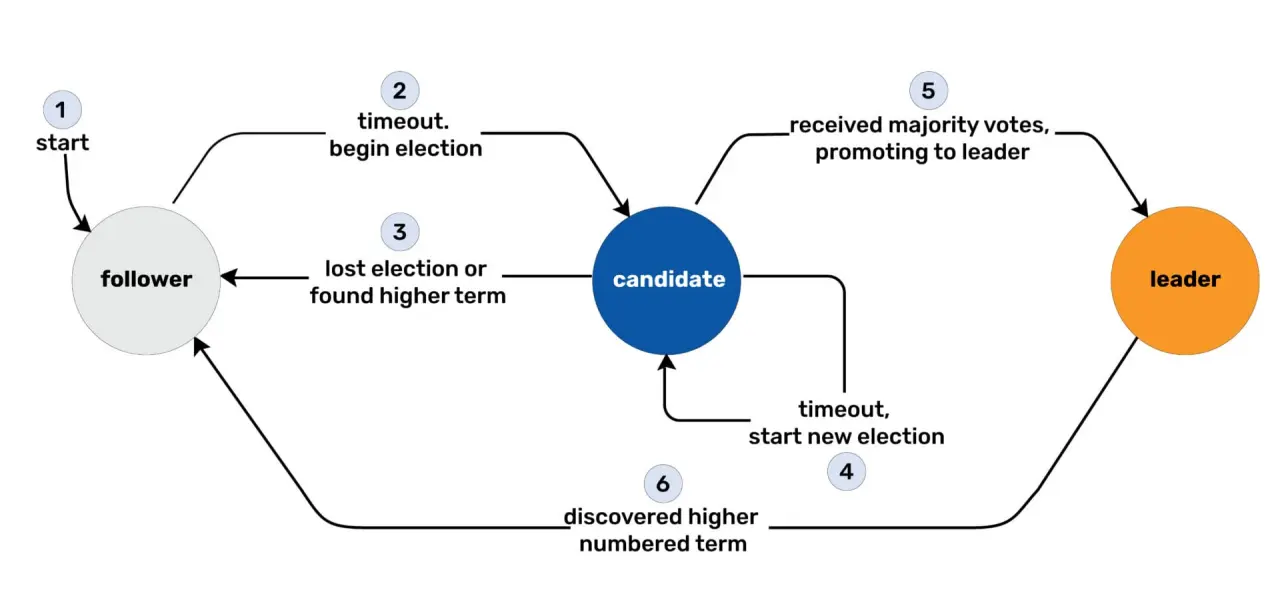
The leader node:
- Handles all write operations.
- Replicates data to follower nodes.
- Sends periodic heartbeats to confirm its leadership.
Write Consistency
ETCD ensures that a write is considered successful only when acknowledged by a majority (quorum) of nodes. For instance:
- In a 3-node cluster, 2 nodes must confirm a write.
- If 1 node is unavailable, quorum is still maintained, and writes proceed.
This mechanism ensures data consistency across the cluster.
Understanding Quorum and Fault Tolerance
Quorum refers to the minimum number of nodes that must be available for the cluster to remain functional and process writes. It is calculated as:
Quorum = (Total Nodes / 2) + 1
Example Quorums:
- 3 nodes → Quorum: 2 (tolerates 1 failure).
- 5 nodes → Quorum: 3 (tolerates 2 failures).
- 7 nodes → Quorum: 4 (tolerates 3 failures).
Why Use Odd Numbers?
Odd numbers of nodes are recommended to prevent issues during network partitions. In an even-numbered cluster split, neither side achieves quorum, leading to a failed cluster.
Cluster Sizing and Topology
Recommended Cluster Sizes
- 3 Nodes: Minimum for high availability.
- 5 Nodes: Improved fault tolerance (tolerates up to 2 failures).
- 7 Nodes: Useful for mission-critical environments but rarely necessary for most setups.
Topologies for ETCD
-
Stacked Topology:
- ETCD runs on the same nodes as the control plane components.
- Simpler to manage but carries higher risk—losing a node impacts both ETCD and the control plane.
-
External Topology:
- ETCD runs on dedicated nodes separate from the control plane.
- More resilient but requires additional infrastructure and management overhead.
For an external topology, ensure API servers are configured to connect to all ETCD nodes:
$ cat /etc/systemd/system/kube-apiserver.service
[Service]
ExecStart=/usr/local/bin/kube-apiserver \\
--advertise-address=$(INTERNAL_IP) \\
--allow-privileged=true \\
--apiserver-count=3 \\
--etcd-cafile=/var/lib/kubernetes/ca.pem \\
--etcd-keyfile=/var/lib/kubernetes/kubernetes-key.pem \\
--etcd-servers=https://10.240.0.12:2379,https://10.240.0.13:2379
Practical Configuration of ETCD
Steps to Set Up ETCD
-
Download the latest ETCD binaries.
# Fetch the latest ETCD version ETCD_VERSION=$(curl -sL https://api.github.com/repos/etcd-io/etcd/releases/latest | grep tag_name | cut -d '"' -f 4) # Download the ETCD binary wget https://github.com/etcd-io/etcd/releases/download/${ETCD_VERSION}/etcd-${ETCD_VERSION}-linux-amd64.tar.gz -
Extract and Create Required Directory Structure:
# Extract the tarball tar -xvf etcd-${ETCD_VERSION}-linux-amd64.tar.gz # Move the binaries to /usr/local/bin sudo mv etcd-${ETCD_VERSION}-linux-amd64/etcd* /usr/local/bin/ # Create required directories for data and certificates sudo mkdir -p /var/lib/etcd /etc/etcd/certs sudo chown -R etcd:etcd /var/lib/etcd -
Copy Over Certificate Files As discussed in the TLS Certificate Section, generate the required certificates and copy them to the /etc/etcd/certs directory on all ETCD nodes.
Certificate files needed:
- ca.crt (CA certificate)
- server.crt and server.key (Server certificate and key)
- peer.crt and peer.key (Peer communication certificate and key)
scp ca.crt server.crt server.key peer.crt peer.key user@node-2:/etc/etcd/certs/Set secure permissions for these files:
sudo chmod 600 /etc/etcd/certs/*.key sudo chmod 644 /etc/etcd/certs/*.crt sudo chown -R etcd:etcd /etc/etcd/certs/ -
Verify the installation
etcd --version -
Configure the ETCD service, including peer and cluster information
$ cat etcd.service [Unit] Description=etcd key-value store Documentation=https://etcd.io/docs/ After=network.target [Service] User=etcd Type=notify Environment="ETCD_UNSUPPORTED_ARCH=arm64" ExecStart=/usr/local/bin/etcd \ --name ${ETCD_NAME} \ --data-dir /var/lib/etcd \ --listen-client-urls https://${INTERNAL_IP}:2379,https://127.0.0.1:2379 \ --advertise-client-urls https://${INTERNAL_IP}:2379 \ --listen-peer-urls https://${INTERNAL_IP}:2380 \ --initial-advertise-peer-urls https://${INTERNAL_IP}:2380 \ --initial-cluster "etcd1=https://${ETCD1_IP}:2380,etcd2=https://${ETCD2_IP}:2380,etcd3=https://${ETCD3_IP}:2380" \ --initial-cluster-state new \ --client-cert-auth \ --trusted-ca-file /etc/etcd/certs/ca.crt \ --cert-file /etc/etcd/certs/server.crt \ --key-file /etc/etcd/certs/server.key \ --peer-client-cert-auth \ --peer-trusted-ca-file /etc/etcd/certs/ca.crt \ --peer-cert-file /etc/etcd/certs/peer.crt \ --peer-key-file /etc/etcd/certs/peer.key Restart=on-failure LimitNOFILE=40000 [Install] WantedBy=multi-user.target
This configuration ensures that etcd operates securely by enabling TLS encryption for both client and peer communications.
- The following flags configure TLS for client-server communication:
--listen-client-urls https://${INTERNAL_IP}:2379,https://127.0.0.1:2379
--advertise-client-urls https://${INTERNAL_IP}:2379
--client-cert-auth
--trusted-ca-file /etc/etcd/certs/ca.crt
--cert-file /etc/etcd/certs/server.crt
--key-file /etc/etcd/certs/server.key
- The following flags ensure secure communication between etcd peers (etcd nodes in the cluster):
--listen-peer-urls https://${INTERNAL_IP}:2380
--initial-advertise-peer-urls https://${INTERNAL_IP}:2380
--initial-cluster "etcd1=https://${ETCD1_IP}:2380,etcd2=https://${ETCD2_IP}:2380,etcd3=https://${ETCD3_IP}:2380"
--peer-client-cert-auth
--peer-trusted-ca-file /etc/etcd/certs/ca.crt
--peer-cert-file /etc/etcd/certs/peer.crt
--peer-key-file /etc/etcd/certs/peer.key
Now that your etcd cluster is set up and running securely with TLS, you can use the etcdctl utility to interact with it. Make sure you set the environment variable ETCDCTL_API=3 to use the latest version of the etcd API. From here, you can explore more advanced operations like checking the cluster health, adding members, and watching keys for changes.
Set the API Version
Ensure you’re using the v3 API:
$ export ETCDCTL_API=3
Store a Key-Value Pair
Add a key-value pair to etcd:
$ etcdctl put greeting "Hello, etcd!"
Retrieve a Key
Fetch the value of the stored key:
$ etcdctl get greeting
greeting
Hello, etcd!
List All Keys
List all the keys stored in the cluster:
$ etcdctl get / --prefix --keys-only
greeting
Now that you can store and retrieve data, try exploring more commands:
- Watch a key for changes:
etcdctl watch greeting
- Check the cluster health:
etcdctl endpoint health
These commands validate that your cluster is functional and ready for more advanced use cases.